在AWS上部署llama-2
本教程介绍如何使用Walrus在AWS上使用CPU部署llama-2,并通过友好的web UI来使用它。
先决条件
想要跟随本教程,您将需要:
注意: 虽然使用CPU比GPU便宜,但仍会给您带来对应EC2实例的开销。
简单的方式
通过Walrus,您只需要一分钟左右就可以在AWS上运行一个可用的llama-2实例,并有一个友好的web UI来使用它。只需要按照以下步骤操作:
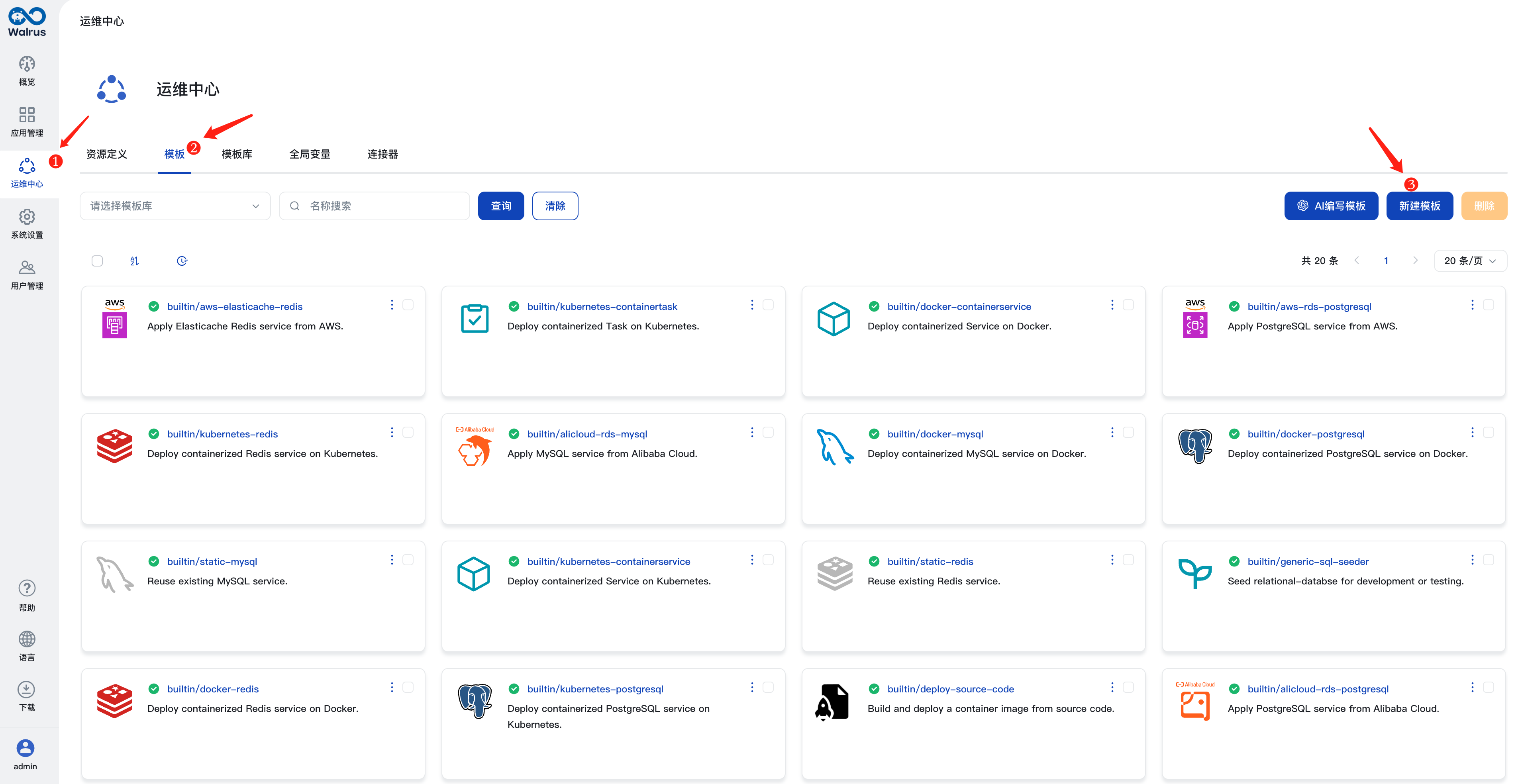
添加llama-2模板
- 登入Walrus,点击左侧导航中的
运维中心,在模板标签页中,点击新建模板按钮。 - 填入模板名称,例如
llama-2。 - 在来源中填写
https://github.com/walrus-tutorials/llama2-on-aws。 - 点击
保存。
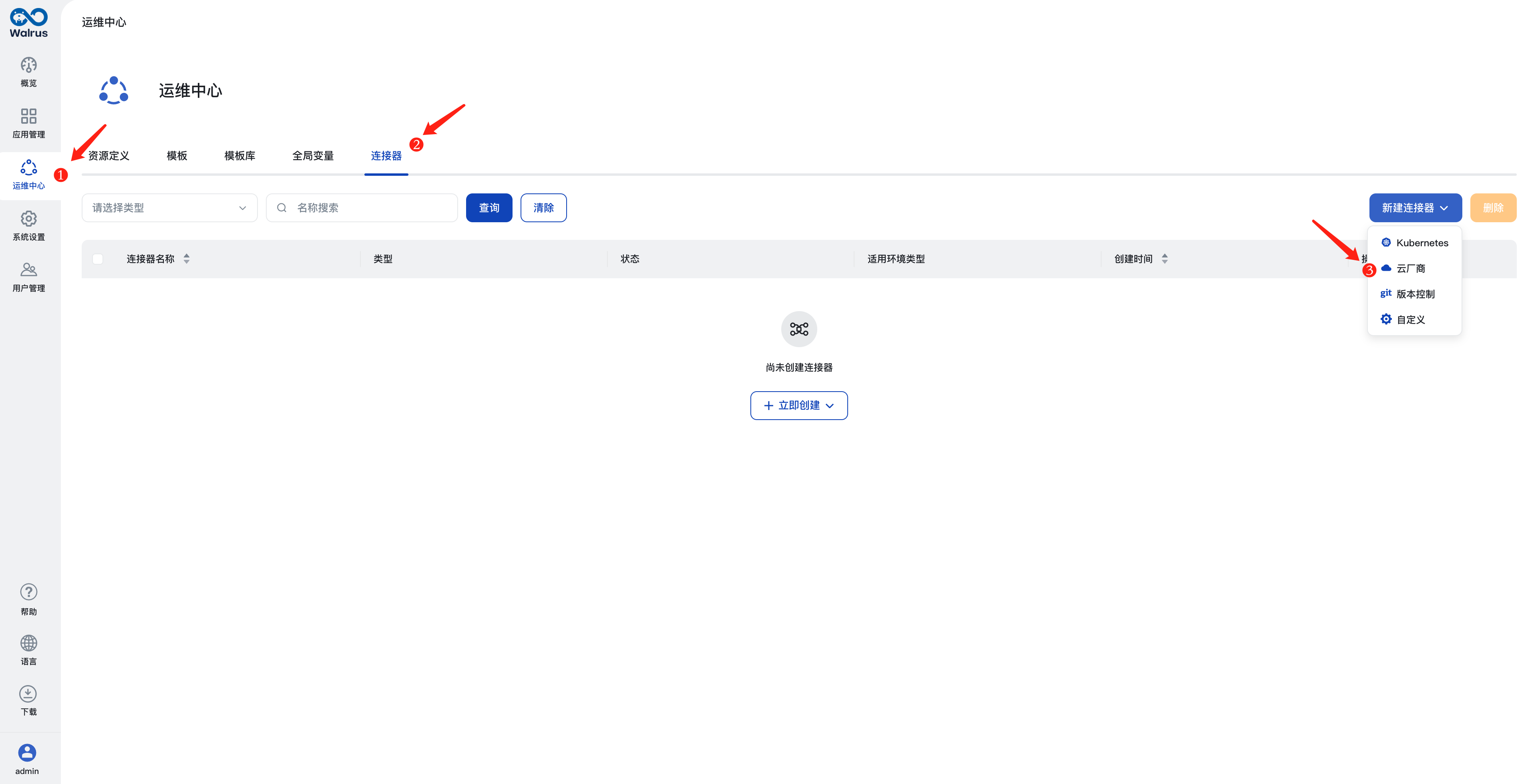
配置AWS凭证
- 在左侧导航中点击
运维中心,点击连接器标签页。 - 点击
新建连接器按钮,选择云厂商类型。 - 填入连接器名称,例如
aws。 - 在
适用环境类型选项中选择开发。 - 在
类型选项中选择AWS。 - 在
区域选项中选择东京(ap-northeast-1)。 - 点击
保存。
注意: 这里使用指定的区域,是因为后续使用了该区域下指定的AMI。如果您想使用其它区域,可以将该AMI导出到您的区域。或参考后续章节了解如何从零构建llama-2镜像。
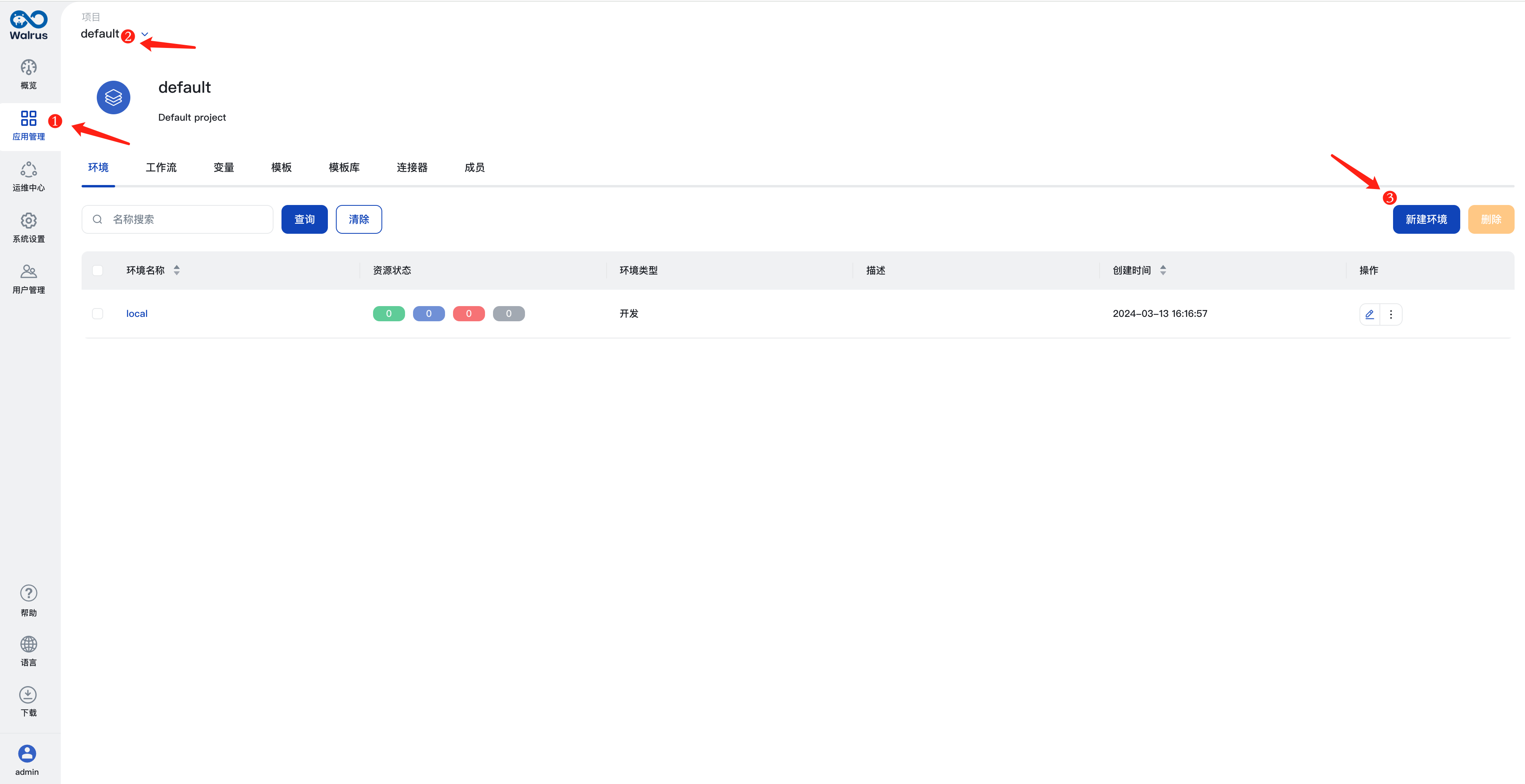
配置环境
- 在左侧导航中点击
应用管理,点击面包屑中的default项目。 - 在
环境标签页中,点击新建环境按钮。 - 填入环境名称,例如
dev。 - 在
环境类型选项中选择开发。 - 点击
添加连接器按钮,选择上一步创建的aws连接器。 - 点击
保存。
创建llama-2服务
- 在
环境标签页中点击dev环境的名称,进入环境视图。 - 点击
新建资源按钮。 - 填入服务名称,例如
my-llama-2。 - 启用
使用模板选项。 - 在
模板选项中选择llama-2。 - 点击
保存。
注意: 默认的配置假定您的AWS账号在对应区域有一个默认的VPC。如果您没有默认的VPC,请到AWS的VPC控制台创建一个新的VPC,并关联一个子网和安全组到该VPC。 安全组需要开放7860 TCP端口(用于访问llama-2 web UI)。您可以在配置中设置您的VPC名字和安全组名字。
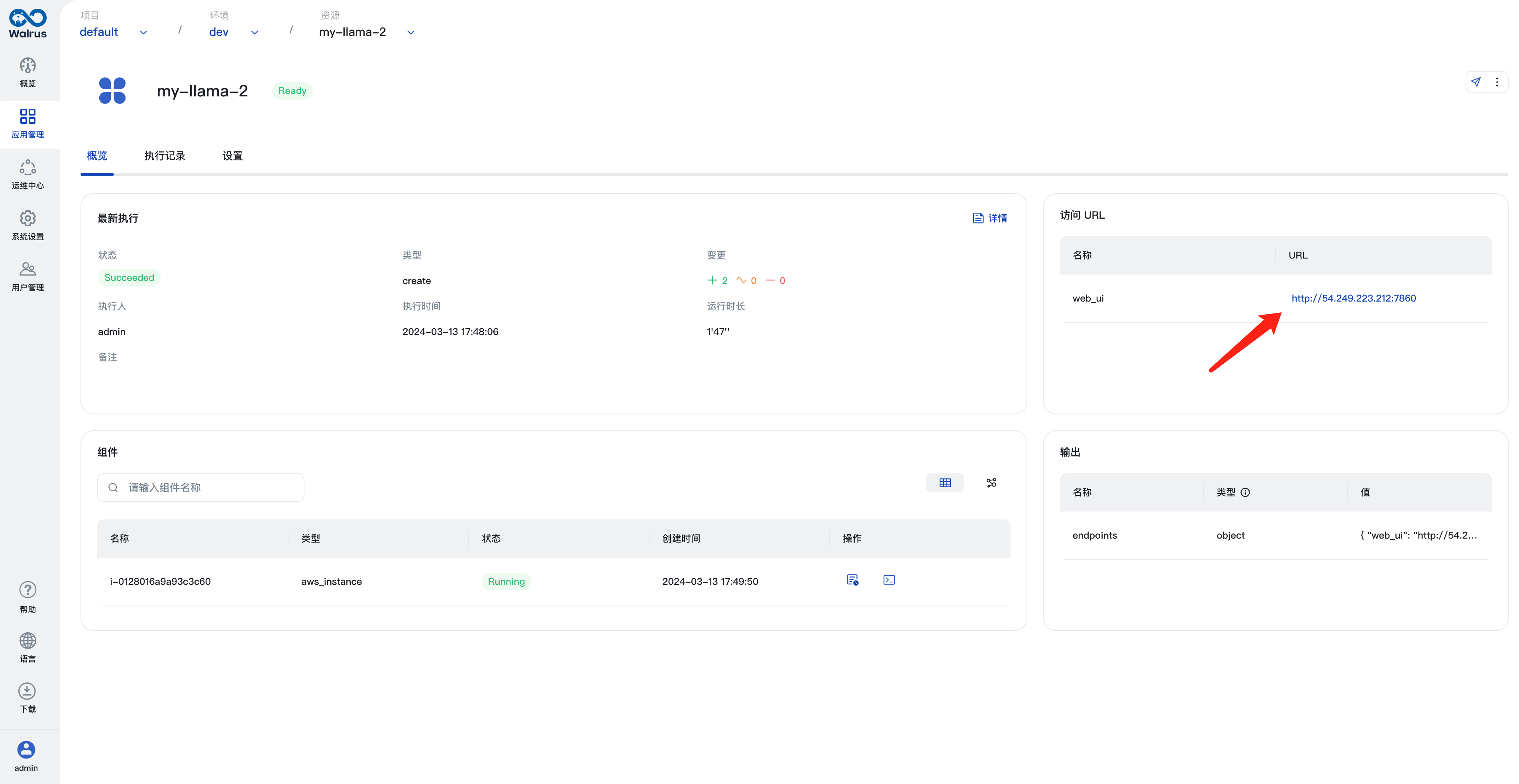
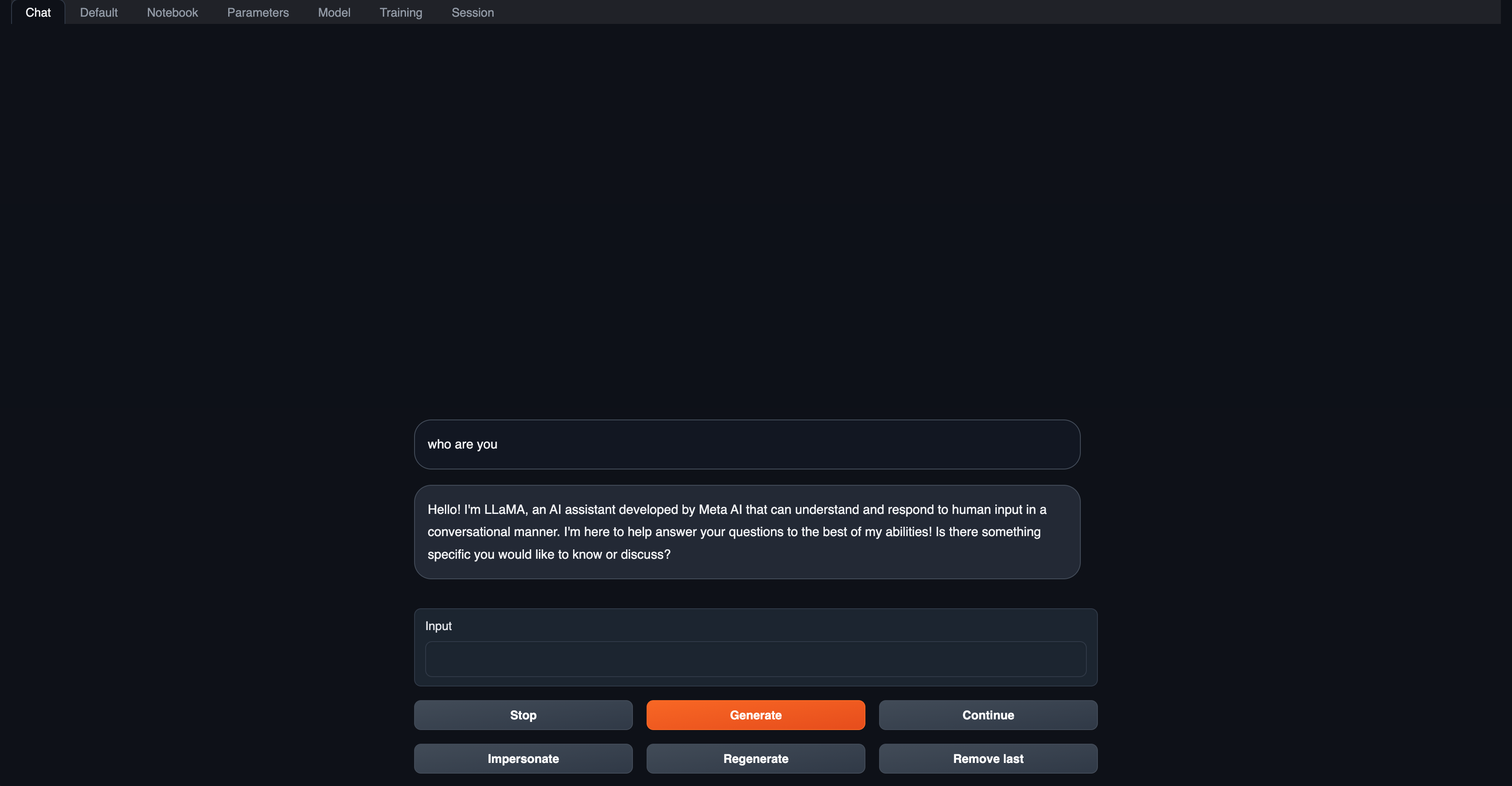
访问llama-2 web UI
您可以在llama-2资源的详情页中看到它的部署和运行状态。等待llama-2资源完成部署后,您可以通过Walrus UI点击它的访问链接来访问它的web UI。
深入了解:从零开始构建llama-2镜像
上述指引中使用了打包好的llama-2镜像。好处显而易见,在创建一个新的llama-2实例的时候您不再需要花费时间下载大语言模型(通常有着可观的文件大小)以及构建推理服务。 本节将介绍上述这样的llama-2镜像是如何构建的。
您可以在这里查看完整的构建过程。
其中的关键步骤如下:
# get text-generation-webui
git clone https://github.com/oobabooga/text-generation-webui && cd text-generation-webui
# configure text-generation-webui
ln -s docker/{Dockerfile,docker-compose.yml,.dockerignore} .
cp docker/.env.example .env
sed -i '/^CLI_ARGS=/s/.*/CLI_ARGS=--model llama-2-7b-chat.ggmlv3.q4_K_M.bin --wbits 4 --listen --auto-devices/' .env
sed -i '/^\s*deploy:/,$d' docker/docker-compose.yml
# get quantized llama-2
curl -L https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q4_K_M.bin --output ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin
# build and run
docker compose up --build
简单来说,该过程下载了量化的llama-2-7b-chat模型,然后构建并使用text-generation-webui来启动llama-2服务。